
Test and Behavior Driven Development For Big Data
Reading Time: 16 Minutes
by | April 13, 2018

What is Test Driven Development?
Test-Driven Development (TDD) is a software development process which includes test-first development. It means that the developer first writes a fully automated test case before writing the production code to fulfil that test and refactoring. Steps for the same are given below -
-
Firstly, add a test.
-
Run all the tests and see if any new test fails.
-
Update the code to make it pass the new tests.
-
Run the test again and if they fail then refactor again and repeat.
Test Driven Development (TDD) Tools For Big Data
Understanding Apache Nifi
Apache Nifi is a widely used framework for Data Ingestion where we can define our workflows to ingest data from a particular source and route it to multiple destinations by defining processors, controller services etc.
It also provides some processors to do pre-processing work like conversion from one format to the other, adding extra attributes to the incoming data.
While developing our workflows in Apache Nifi, it is very important to test our workflows and controller services used by them.
-
Apache Nifi Workflows
Nifi workflow comprises of various processors which takes flow files as input and outputs and Nifi Workflow takes care of output to be passed to next processor as input. Flow Files are actual data which has been fetched from external sources like Amazon S3, HDFS, Databases, API etc.
-
Controller Services
Controller services are inbuilt services offered by Nifi which are used by processors to connect to external sources like DBCP Connection Pool, Hive Connector services or transformation services like defining AVRO Schema Parser for our external sources. So basically, we configure our controller services separately in Nifi, so that we can use our data sources in an optimized manner.
These are some tools used for Nifi Workflow and custom processor testing
-
NiFi mock module for Unit Testing Custom Processor
-
Generate FlowFile for Stress/Load Testing
Nifi-mock module for Testing Custom Processor
We can also build any custom processors according to our requirements. Nifi offers this module to test the custom processor.
Nifi-mock module aims to test every processor with its functional behavior like some processors in the Apache Nifi workflow will be for transforming data from one format to another format, adding new attributes (Data Enrichment) or removing unnecessary attributes(Data Cleaning) from flow files.
Nifi-mock provides a Test Runner class in which we can write test cases for each processor and set up mock data for them and invoke them using @OnTrigger annotation.
All Mock Data setup by us will be converted into Flow files and create ProcessSessions and ProcessContexts to start the job for Nifi processors and also invoke other lifecycle methods for a processor.
So, TestRunner class executes the test cases in the same way as it runs on staging or production environment and hence ensures us that our processors will work properly in the production environment.
Stress Testing vs Load Testing using Generate FlowFile
Now, another important aspect of testing is Load Testing. We must validate our Nifi workflow for data coming at a higher velocity and how it behaves at that point.
For this, Nifi provides Generate FlowFile processor which we can use as our Mock data source and we can specify the number of files we want to generate along with their size. So this will keep generating the sample file and we can test the flow with a heavy workload.
Apache Kafka Cluster Architecture
Apache Kafka is widely used as a Real-time streaming source for Big Data Platform. So it is also a part of Data Ingestion Layer, as Nifi collects the data from our Data Source and then writes it on Kafka Topics and Kafka provides very low latency and high performance read/writes and is used as streaming sources by a lot of consumers like Apache Spark, Apache Flink, Apache Storm etc.
It is very important to test the connectivity, performance, and concurrency before using it in the production.
Various tools used are -
-
Embedded Kafka for Unit Testing.
-
DuckTape for Integration and Performance Testing.
-
Kafka’s inbuilt Benchmarking Scripts for Stress/Load Testing.
Unit Testing with Embedded Kafka
Embedded Kafka library is used to test our producer and consumer code scripts with Kafka.
For example, embedded Kafka provides an in-memory broker by which we can launch Kafka and Apache ZooKeeper programmatically and then test our producer and consumer functions within the code.
Embedded Kafka will start the zookeeper and Kafka on our defined ports, and it will automatically shut down the zookeeper and Kafka service after completing the test.
Integration Testing
We can do integration testing just like Unit testing using Embedded Kafka, but we will be testing other components which are using Kafka like in our use case.
We will be using Apache Nifi as our Kafka producer and then Spark as our Kafka Consumer. So, we will be doing integration testing for verifying any data loss or mismatch between Nifi and Kafka topic or Kaka and Spark topic.
Stress Testing & Performance Testing using DuckTape Library
Ducktape library is used for System Integration and Performance Testing for Kafka. Also, Kafka installation provides Kafka-run-class.sh script by which we can test our Kafka single/multi-node cluster by running KafkaProducer from a script and put as much load as we want and in parallel, we can start our consumer also from the script and set a limit around 1 lac to 1 million to check that how many messages Kafka can ingest. So, we can test both stresses as well as performance testing.
Overview of Apache Spark
Apache Spark is widely used as high processing and computing engine which processes a huge amount of data and runs complex analytical operations on it. Further, Spark ML and Spark MLlib modules offer us to run Machine Learning Algorithms on a huge amount of data and also offers us API’s to build our custom models on top of it.
However, Spark API’s enables us to write our code concisely and we, can skip test cases, but still, there are a lot of other parameters in spark jobs which should be tested before we move our code to production.
Spark offers a local mode in our code for making test case writing in Spark easy. The local mode will create a Spark cluster on our local machine out of the box.
While using pytest annotations, we should break our Spark job into methods, meaning the minimum amount of code in decoupling manner.
‘pytest’ also offers the setting scope of our Spark contexts and other objects we used in our Spark job. Also, to fasten our process of testing, we can set the scope of Sparkcontext to the session, so that we can reuse the Sparkcontext object in other test cases.
To test our ETL process in Spark job like loading data from external data sources into DataFrames/DataSets and then running transformation on it, we can use HiveContext test fixture to convert dummy data to data frames using HiveContext objects.
There are many ways to perform unit testing with Spark. We can either use Junit or Scalatest for developing testing suite for a Spark application from scratch or we can use Spark Testing Base, a popular spark unit testing framework developed by Holden Karau.
Testing Tools for Test Driven Development with Apache Spark
-
Spark Testing Base library for Spark Jobs written in Java and Scala.
-
‘pytest’ library for pySpark Jobs.
Setting up Environment for Test Driven Development (TDD)
In the previous section, we have explained various frameworks/tools which we can use for testing our Big Data Components. Now here, we will look at the environmental setup and implementation of various testing frameworks we have discussed above.
Apache Nifi Testing Framework
In Nifi, we can also build custom processors as per our requirement. To use those custom processor we also need to perform some test cases before using them in production.
Unit Testing in Apache Nifi
The first thing we require for the unit test in Apache Nifi is to use necessary dependencies from Apache Maven.
<dependency>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-mock</artifactId>
<version>${nifi.version}</version>
<scope>test</scope>
</dependency>
And these are the things which we need to include in our test case for the custom processor - TestRunner, TestRunners and MockFlowFile.
CustomProcessorTest.java
@org.junit.Test
public void testOnTrigger() throws IOException {
// Content to be mock
InputStream content = new ByteArrayInputStream("{\"hello\":\"nifi rocks\"}".getBytes());
// Generate a test runner to mock a processor in a flow
TestRunner runner = TestRunners.newTestRunner(new CustomProcessor());
// Add properites
runner.setProperty(JsonProcessor.JSON_PATH, "$.hello");
// Add the content to the runner
runner.enqueue(content);
// Run the enqueued content, it also takes an int = number of contents queued
runner.run(1);
// All results were processed with out failure
runner.assertQueueEmpty();
// If you need to read or do additional tests on results you can access the content
List<MockFlowFile> results = runner.getFlowFilesForRelationship(JsonProcessor.SUCCESS);
assertTrue("1 match", results.size() == 1);
MockFlowFile result = results.get(0);
String resultValue = new String(runner.getContentAsByteArray(result));
System.out.println("Match: " + IOUtils.toString(runner.getContentAsByteArray(result)));
// Test attributes and content
result.assertAttributeEquals(JsonProcessor.MATCH_ATTR, "test");
result.assertContentEquals("test");
}
Stress Testing and Load Testing Amazon S3
Defining GenerateFlowFile
We can configure these things in GenerateFlowFile -
-
File Size - Here we can choose file size that we are going to create for the load test.
-
Batch Size - Here we can define the batch size that we are going to create in a single invocation.
-
Data format - Here we can specify the data format. Available formats are text and binary.
Defining Control Rate - In this processor, we can control the rate of data transfer of the flow. This can be done in two ways: one is on the basis number of flow files count and the other is on the basis of flow files data size.
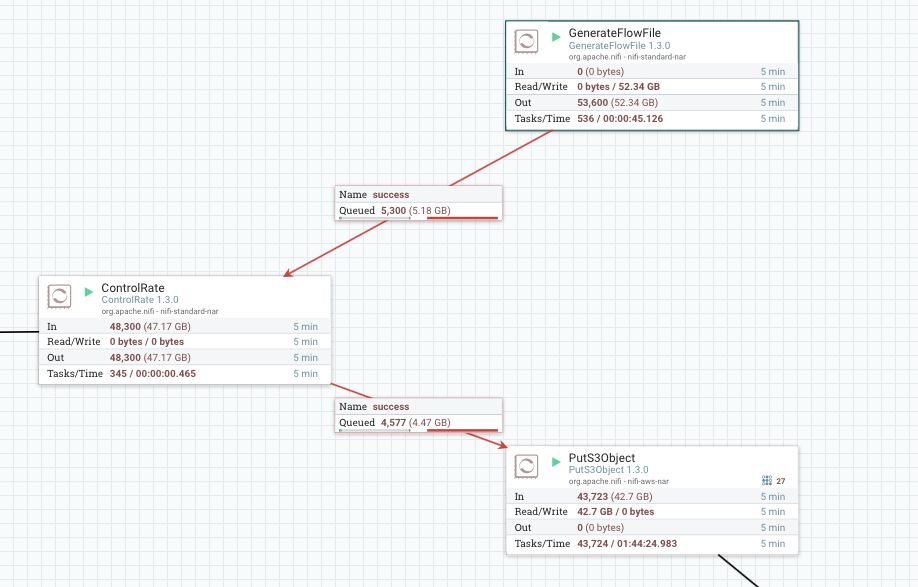
Apache Kafka Testing Framework
Apache Kafka testing includes testing using Embedded Kafka and benchmarking.Testing is done using pre-packaged tools provided by Kafka
Unit Testing using Embedded Kafka in Java
Example -
- Adding dependency to your pom.xml file -
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
- Following is the snippet of test written using JUnit.
@Test
public void producerConsumerTest() throws Exception {
//Create a consumer
ConsumerIterator<String, String> consumerIterator = buildConsumer(KafkaTest.topic);
//Create a producer
Producer kafkaProducer = new KafkaProducer(producerProps());
//send a message
kafkaProducer.send(new ProducerRecord(KafkaTest.topic, "message")).get();
//read it back
MessageAndMetadata<String, String> messageAndMetadata = consumerIterator.next();
String value = messageAndMetadata.message();
assertThat(value, is("message"));
}
Unit Testing using Embedded Kafka in Python
Let us consider the following unit to test -
Producer.py
def test_kafka_producer_proper_record_metadata(kafka_broker, compression):
connect_str = ':'.join([kafka_broker.host, str(kafka_broker.port)])
producer = KafkaProducer(bootstrap_servers=connect_str,
retries=5,
max_block_ms=10000,
compression_type=compression)
magic = producer._max_usable_produce_magic()
topic = random_string(5)
future = producer.send(
topic,
value=b"Simple value", key=b"Simple key", timestamp_ms=9999999,
partition=0)
record = future.get(timeout=5)
assert record is not None
assert record.topic == topic
assert record.partition == 0
assert record.topic_partition == TopicPartition(topic, 0)
assert record.offset == 0
if magic >= 1:
assert record.timestamp == 9999999
else:
assert record.timestamp == -1 # NO_TIMESTAMP
if magic >= 2:
assert record.checksum is None
elif magic == 1:
assert record.checksum == 1370034956
else:
assert record.checksum == 3296137851
assert record.serialized_key_size == 10
assert record.serialized_value_size == 12
# generated timestamp case is skipped for broker 0.9 and below
if magic == 0:
return
send_time = time.time() * 1000
future = producer.send(
topic,
value=b"Simple value", key=b"Simple key", timestamp_ms=None,
partition=0)
record = future.get(timeout=5)
assert abs(record.timestamp - send_time) <= 1000
Consumer.py
def assert_kafka(self, expected_file_name):
kafka_client = KafkaClient(KAFKA_SERVER)
consumer = SimpleConsumer(kafka_client, b"my_group", KAFKA_TOPIC.encode("utf8"),iter_timeout=1)
consumer.seek(1, 0)
actual = ""
for msg in consumer:
actual += msg.message.value.decode('utf8')+"\n"
expected = pkg_resources.resource_string(__name__, expected_file_name).decode('utf8')
self.assertEqual(actual, expected)
Unit Testing using Embedded Kafka in Scala
Let us consider the following unit to test -
Producer.scala
case class Employee(name: String, id: Int)
class Producer {
def writeToKafka(topic: String) = {
val props = new Properties()
props.put("bootstrap.servers", "localhost:9092")
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "serde.UserSerializer")
val producer = new KafkaProducer[String, Employee](props)
for (i < -1 to 30) {
val record = new ProducerRecord[String, Employee](topic, Employee("name" + i, i))
producer.send(record)
}
}
}
object ProducerMain extends App {
val topic = "my-kafka-topic"
(new Producer).writeToKafka(topic)
}
Consumer.scala
class Consumer {
def consumeFromKafka(topic: String) = {
val props = new Properties()
props.put("bootstrap.servers", "localhost:9092")
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.put("value.deserializer", "serde.UserDeserializer")
props.put("group.id", "something")
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
val consumer: KafkaConsumer[String, Employee] = new KafkaConsumer[String, Employee](props)
consumer.subscribe(util.Collections.singletonList(topic))
val record = consumer.poll(5000).asScala.toList.map(_.value())
record
}
}
object ConsumerMain extends App {
val topic = "my-kafka-topic"
(new Consumer).consumeFromKafka(topic)
}
- Adding dependency to your build.sbt -
“net.manub” %% “scalatest-embedded-kafka” % “0.14.0” % “test”
- Have your TestSpec extend the EmbeddedKafka trait.
withRunningKafka automatically start the zookeeper and Kafka server and also shut these down after the test
class KafkaSpec extends FlatSpec with EmbeddedKafka with BeforeAndAfterAll {
val topicName = "my-kafka-topic"
val producer = new Producer
val consumer = new Consumer
//We can also use manual zookeeper and kafka port.
//Zookeeper and Kafka will be started by providing an implicit EmbeddedKafkaConfig
// implicit val config = EmbeddedKafkaConfig(kafkaPort = 9095, zooKeeperPort = 2182)
override def beforeAll(): Unit = {
EmbeddedKafka.start()
}
it should "publish synchronously data to Kafka" in {
producer.writeToKafka(topicName)
val response = consumeFirstStringMessageFrom(topicName)
assert(Some(response).isDefined)
}
it should "consume message from published topic" in {
implicit val serializer = new UserSerializer
Val list = List(Employee("Allen", 1), Employee("Roff", 2), Employee("Ady", 3),
Employee("peter", 4), Employee("jamer", 5), Employee("tony", 6))
list.map(publishToKafka(topicName, _))
val response = consumer.consumeFromKafka(topicName)
assert(response.size > 6)
}
override def afterAll(): Unit = {
EmbeddedKafka.stop()
}
}
Benchmarking for Apache Kafka Producer
We can use pre-packaged performance testing tools to perform the load testing on both producer and consumer.
-
Step 1 - Creating Kafka topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test-topic16 --partitions 16 --replication-factor 1
We can choose a number of partitions and replication factors according to the Kafka cluster.
-
Step 2 -
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic test-topic16 --num-records 50000000 --record-size 100 --throughput -1 --producer-props acks=1 bootstrap.servers=localhost:9092 buffer.memory=104857600 batch.size=9000
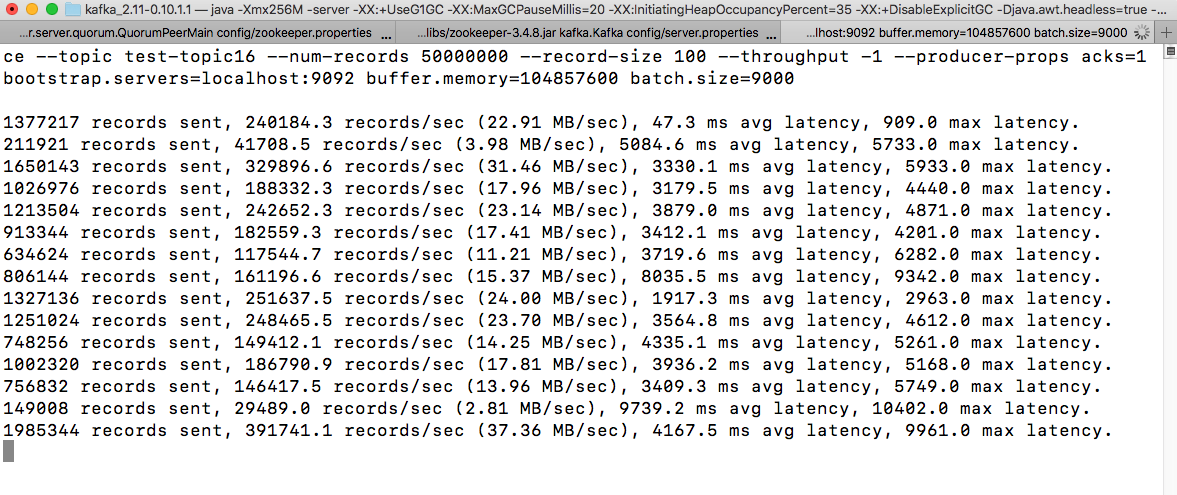
Above script gives us the results of messages processed by the Kafka producer. We can use any required message size and number of messages for which we want to perform the stress test. In the above case, we have used 100 bytes of message size and 5 million messages.
Benchmarking for Kafka Consumer
Same pre-packaged performance testing tools can be used for consumer throughput also.
Below script can be used for the consumer throughput -
bin/kafka-consumer-perf-test.sh --zookeeper <zookeeper-address> --messages 50000000 --topic test --threads 1
This script will give results like this -
Navs-Mac-mini:kafka_2.11-0.10.1.1 naveen$ bin/kafka-consumer-perf-test.sh --zookeeper localhost:2181 --messages 20000000 --topic test-topic16 --threads 1
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2017-12-14 14:57:12:484, 2017-12-14 14:57:14:528, 71.6400, 35.0489, 751200, 367514.6771
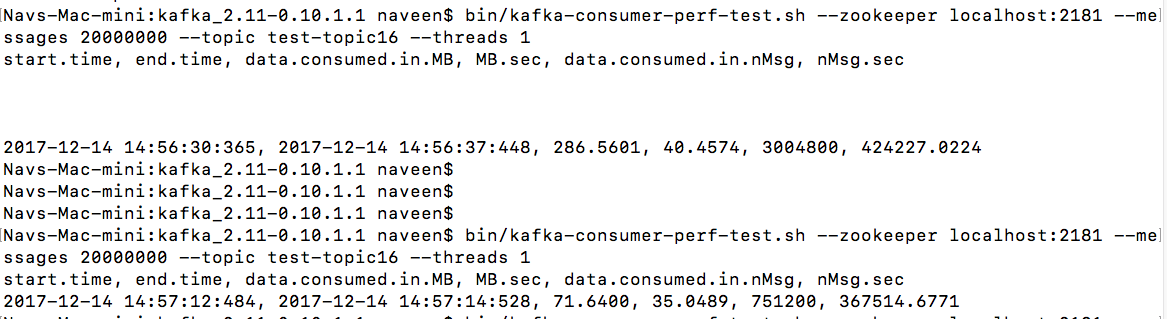
These above scripts will give us the metrics of messages processed per second by the Kafka consumer.
Apache Spark Testing Framework in Java
Testing the spark application using the FunSuite testing style in the scalatest library in order to develop the test.
Let us consider the following unit to test -
public class WordCount {
private static final Pattern SPACE= Pattern.compile(" ");
public int wordCountJob() {
List<Object> list = new ArrayList<>();
SparkSession spark = SparkSession
.builder()
.appName(“wordCount”)
.master(“local[2]”)
.getOrCreate();
JavaRDD<String> lines = spark.read().textFile(“txtFile”).javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
list.add(tuple._1());
}
spark.stop();
return list.size();
}
}
In the above example, we are counting the number of words in a text file; our aim is to test that the above code return the correct size of the list according to the number of words present in the file.
Unit test Using JUnit
-
First, include JUnit dependency in your pom -
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
-
Following is the snippet of test written using JUnit -
public class WordCountTest {
@Test
public void testwordCountJob() {
int listSize = new WordCount().wordCountJob();
assertEquals(4,listSize);
}
}
On Executing the Program -
If the test passes -

If the test fails -

Apache Spark Testing with Pyspark
Testing the pyspark application using pytest testing style in library in order to develop the test.
Let us consider the following unit to test -
def do_word_counts(lines):
""" count of words in an rdd of lines """
counts = (lines.flatMap(lambda x: x.split())
.map(lambda x: (x, 1))
.reduceByKey(add)
)
results = {word: count for word, count in counts.collect()}
return results
To test this function, we need a SparkContext fixture. A test fixture is a fixed state of a set of objects that can be used as a consistent baseline for running tests. We’ll create a local mode SparkContext and decorate it with a py.test fixture
@pytest.fixture(scope="session")
def spark_context(request):
""" fixture for creating a spark context
Args:
request: pytest.FixtureRequest object
"""
conf = (SparkConf().setMaster("local[2]").setAppName("pytest-pyspark-local-testing"))
sc = SparkContext(conf=conf)
request.addfinalizer(lambda: sc.stop())
quiet_py4j()
return sc
Creating a Spark Context (even in local mode) takes time, so we want to reuse it. The scope=session argument does exactly that: allows reusing the context for all tests in the session.
One can also set the scope=module to get a fresh context for tests in a module.
Now the SparkContext can be used to write a unit test for word count:
pytestmark = pytest.mark.usefixtures("spark_context")
def test_do_word_counts(spark_context):
""" test word couting
Args:
spark_context: test fixture SparkContext
"""
test_input = [
' hello spark ',
' hello again spark spark'
]
input_rdd = spark_context.parallelize(test_input, 1)
results = wordcount.do_word_counts(input_rdd)
expected_results = {'hello':2, 'spark':3, 'again':1}
assert results == expected_results
Unit Testing Using The Dataframe API
Here is another example for testing a function using the Dataframes API which is also used by Spark SQL. This function counts the occurrences of a name in a dataframe (read from a bunch of json).
To test our json counts function, we need to create a HiveContext test fixture so that we can read in json using its nifty jsonRDD function. The rest of the function is similar to the word counts test.
pytestmark = pytest.mark.usefixtures("spark_context", "hive_context")
def test_do_json_counts(spark_context, hive_context):
""" test that a single event is parsed correctly
Args:
spark_context: test fixture SparkContext
hive_context: test fixture HiveContext
"""
test_input = [
{'name': 'vikas'},
{'name': 'vikas'},
{'name': 'john'},
{'name': 'jane'},
]
input_rdd = spark_context.parallelize(test_input, 1)
df = hive_context.jsonRDD(input_rdd)
results = jsoncount.do_json_counts(df, 'vikas')
expected_results = 2
assert results == expected_results
Apache Spark Streaming Unit Test Example
This final example tests a Spark Streaming application. Spark streaming’s key abstraction is a discretized stream or a DStream, which is basically a sequence of RDDs. Here is a streaming version of our word counting example that operates on a DStream and returns a stream of counts.
from operator import add
def do_streaming_word_counts(lines):
""" count of words in a dstream of lines """
counts_stream = (lines.flatMap(lambda x: x.split())
.map(lambda x: (x, 1))
.reduceByKey(add)
)
return counts_stream
You guessed it, we need a StreamingContext test fixture. We also need to create a DStream with test data. StreamingContext has a really nifty queueStream function for just that. Here is the complete unit test for streaming word count:
def test_streaming_word_counts(spark_context, streaming_context):
""" test that a single event is parsed correctly
Args:
spark_context: test fixture SparkContext
streaming__context: test fixture SparkStreamingContext
"""
test_input = [
[
' hello spark ',
' hello again spark spark'
],
[
' hello there again spark spark'
],
]
input_rdds = [sc.parallelize(d, 1) for d in test_input]
input_stream = ssc.queueStream(input_rdds)
tally = wordcount_streaming.do_streaming_word_counts(input_stream)
results = collect_helper(streaming_context, tally, 2)
expected_results = [
[('again', 1), ('hello', 2), ('spark', 3)],
[('again', 1), ('there', 1), ('hello', 1), ('spark', 2)]
]
assert results == expected_results
Apache Spark Testing with Scala
Testing the spark application using the FunSuite testing style in the scalatest library in order to develop the test.
Let us consider the following unit to test -
class WordCount {
Def get(url::String, sc: SparkContext): RDD[(String, Int)] = {
val lines = sc.textFile(url)
Lines.flatMap(_.split(“”)).map((_, 1)).reduceByKey(_ + _)
}
}
In the above example, we are counting the number of words in a text file; our aim is to test the above code.
Method 1 - Unit test using ScalaTest Library
-
First include the following library in the sbt -
libraryDependencies += "org.scalactic" %% "scalactic" % "3.0.4" libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.4" % "test"
-
Following is the snippet of test written using the FunSuite style in scalatest -
Class WordCountTest extendsFunsuite with BeforeAndAfterAll {
private
var sparkConf: SparkConf = _
private
var sc: SparkContext = _
override def beforeAll() {
sparkConf = new SparkConf().setAppName(“Unit - testing - spark”).setMaster(“local”)
sc = new SparkContext(sparkConf)
}
private val wordCount = new WordCount
test(“get word count rdd”) {
val result = wordCount.get(“file.txt”, sc)
assert(result.take(10).length === 10)
}
override def afterAll() {
sc.stop()
}
}
In order to test the above code, we primarily need a spark context, after providing the Spark context in the before method, we simply define the test case.
Using method one we could easily develop a test case if one is familiar with the testing styles in the scalatest. However, it has some disadvantages:
-
A developer needs to explicitly manage to create and destroying of SparkContext.
-
Developer has to write more lines of code for testing
-
Code duplication as before and After step has to be repeated in all TestSuites
Method 2 - Unit Testing Using Spark Testing Base
-
First, include the following library in the sbt -
libraryDependencies += "com.holdenkarau" %% "spark-testing-base" % "2.2.0_0.8.0" % Test
Following is the snippet of test written using spark testing base -
Import org.scalatest.FunSuite
Import com.holdenkarau.spark.testing.SharedSparkContext
Class WordCountTest extends FunSuite with SharedSparkContext {
private val wordCount = new WordCount
test(“get word count rdd”) {
val result = wordCount.get(“file.txt”, sc)
assert(result.take(10).length === 10)
}
}
The above method 2 has the following advantages over method 1 -
-
It provides Succinct code.
-
Provision Rich Test of API.
-
Supports Scala, Java, and Python.
-
It also provides API for testing streaming application.
-
It contains inbuilt RDD comparators.
-
It supports both local and cluster mode testing.
Summary of Test Driven Development
Test-driven development(TDD) is a development technique where the big data engineering team should test all their components first before putting everything in production.
It will help us to prevent the issues in the production environment and keep the performance of our Big Data based solutions predictable. TDD gives a proven way to ensure effective unit and integration testing.
We believe that TDD is an incredible practice and that all software developers should consider during the deployment of Big Data Components and develop code for Big Data Solutions.
How Can Don Help You?
Don follows the Test Driven Development Approach in the development of Enterprise level Applications following Agile Scrum Methodology.
-
Application Modernization Services
Application Modernization means re-platforming, re-hosting, recoding, rearchitecting, re-engineering, interoperability, of the legacy Software application for current business needs. Application Modernization services enable the migration of monolithic applications to new Microservices architecture with Native Cloud Support including the integration of new functionality to create new value from existing application.
Develop, Deploy and Manage Agile Java Application on leading Cloud Service Providers - Google Cloud, Microsoft Azure, AWS, and Container Environment - Docker and Kubernetes.
-
Microservices Architecture
Take a cloud-native approach to building Enterprise Applications for Web and Mobile with Microservices Architecture. An Application based on Microservices Architecture is Small, Messaging–enabled, Bounded by contexts, Autonomously developed, Independently deployable, Decentralized, Language–agnostic, Built and released with automated processes.